起因
模电作业马上就要截止了,然而手中却没有一本趁手的答案以供订正(
然后就收到了一份分享,起初以为是个网盘链接啥的,结果点进去打眼一看,原来是要下 APP??这岂能忍得了,不过为了拿到答案,我还是下了一份应用。熟悉我的朋友们都知道,按照我的做事风格,事情肯定不会到这里就结束了。每次想查个答案还要打开它的 APP,简直不要太憋屈,然而我早已是有着多年逆向工作经验的老油条 (臭不要脸 ^^),这事必须得给它办了
开整
要是放到高中,估计我只会用个小黄鸟抓抓包啥的,不行就开始上 Auto.js 自动化,把每一页都截图。但今时不同往日,在与各种花里胡哨的应用斗智斗勇的过程中我也掌握了不少新手段,今天就拿这「大学搜题酱」来练练手
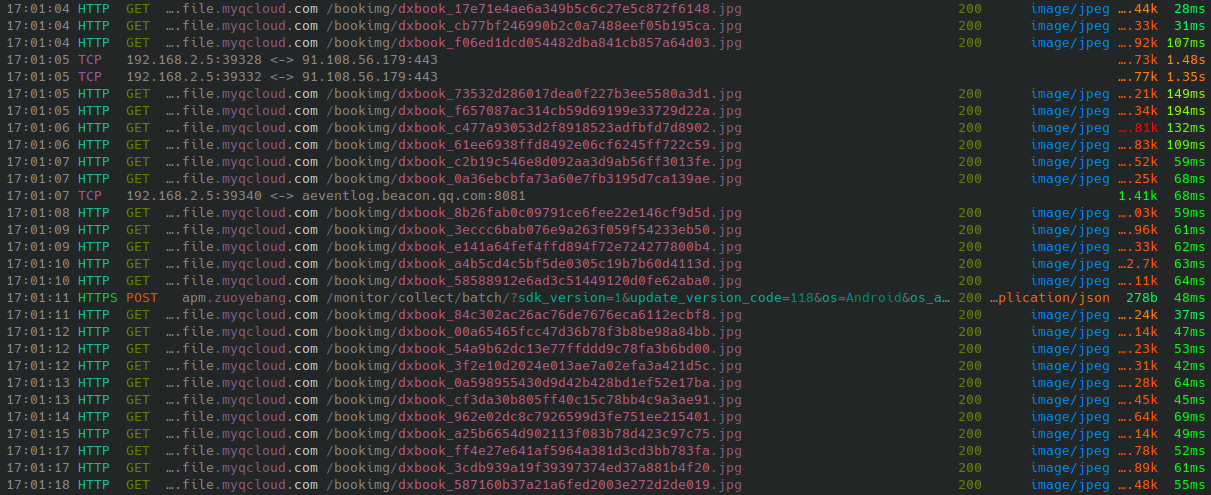
APP 里答案的每一页都是一张图片,那么先从最简单的办法开始,用 mitmproxy 进行一个包的抓,发现 URL 毫无章法,但每一张图片都可以在浏览器直接粘贴 URL 看到,并没有做身份验证:
那么应该会首先有一个 /api/list 之类的请求用于获取每一页图片的 URL 列表,然而这个 APP 有证书固定,mitmproxy 的根证书没法解密它的 https,尝试抓取会产生一个网络错误:
于是开始尝试到 /data/data 底下翻找有没有什么缓存,可能是做了数据加密或者根本就没有缓存,除了一堆乱七八糟的文件以外什么都没找到。不得已只能上魔法了,使用 Activity 或 Intent 记录工具得知查看答案资源的活动名为 AnswerBrowseActivity,查看安装包的 dex 文件,发现有一层腾讯御安全的壳😰,时间成本再次++
用 Frida-DexDump 脱好壳,拉到 jadx 里看一眼,很快就能发现类里有一个 ArrayList<String> 类型的属性,以及对它做了修改的方法,很明显是从启动这个 Activity 的 Intent 中取出了一个叫 INPUT_IMG_URL_LIST 的列表,而这显然就是我们想要的东西:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class AnswerBrowseActivity extends TitleActivity public ArrayList<String> f = new ArrayList<>(); private void f () Intent intent = getIntent(); if (intent != null ) { this .t = getIntent().getIntExtra("INPUT_BOOK_TYPE" , 0 ); this .h = getIntent().getIntExtra("INPUT_PHOTO_POSITION" , 0 ); ArrayList<String> stringArrayListExtra = intent.getStringArrayListExtra("INPUT_IMG_URL_LIST" ); if (stringArrayListExtra != null ) { this .f.clear(); this .f.addAll(stringArrayListExtra); } g(); } } }
接下来只需要把它拿出来就好了,快速搓一个 Xposed 模块,在 onResume 方法开始前查找类型为 ArrayList 的属性,并把它的内容打到 logcat:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class HookEntry : HookHelper "AnswerDump" ) { override fun onApplicationAttach (context: Context ) setDefaultClassLoader(context.classLoader) findMethod("com.zmzx.college.search.activity.booksearch.result.activity.AnswerBrowseActivity" ) { name == "onResume" }!! before { param -> catch { param.thisObject.javaClass.declaredFields.forEach { field -> if (ArrayList::class .java == field.type) { @Suppress("Unchecked_Cast" ) (field.get (param.thisObject) as ArrayList<String>).forEach { Log.i(it) } return @forEach } } } } } }
啊好像 hook Activity#onCreate(Bundle) 就行了,这是个 @CallSuper 标记的方法,每个 Activity 实例都会调到这里:
1 2 3 4 5 6 7 8 9 10 11 12 13 XposedHelpers.findAndHookMethod( Activity::class .java, "onCreate" , Bundle::class .java, object : XC_MethodHook() { override fun beforeHookedMethod (param: MethodHookParam ) with (param.thisObject as Activity) { intent.getStringArrayListExtra("INPUT_IMG_URL_LIST" )?.forEach { Log.i(TAG, it) } } } } )
其实这一步用 Frida 应该会更快,只是我实在懒得修复之前折腾坏的环境(
后面的事情就非常简单了,用 Python 将所有图片一张张下载下来即可,这里直接贴上代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from time import sleepimport httpxwith open ('image_urls.txt' , 'r' ) as fp: lines = fp.readlines() for i, line in enumerate (lines): print (f'[{i+1 :0 >3d} /{len (lines):0 >3d} ]: {line.strip()} ' ) resp = httpx.get(line.strip()) with open (f'images/{i:0 >3d} .jpg' , 'wb' ) as fp: fp.write(resp.content) sleep(0.5 )
最后再整合成 PDF:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import reimport osfrom fpdf import FPDFpdf_file = FPDF(unit='pt' , format =(1389 , 2043 )) pdf_file.set_auto_page_break(False ) pdf_file.set_left_margin(0 ) pdf_file.set_top_margin(0 ) images = os.listdir('images/' ) images.sort(key=lambda s: int (re.search(r'^(\d+)' , s).group(1 ))) for file in images: pdf_file.add_page() print (os.path.join('images/' , file)) pdf_file.image(os.path.join('images/' , file)) pdf_file.output('output.pdf' )
整套流程整合起来其实是可以搓出一个支持应用内直接下载 PDF 的 Xposed 模块的,想了想这应用比较小众,而我又没啥需求,还是算了。